Evaluation#
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn_evaluation import plot, table
sklearn-evluation has two main modules for evaluating classifiers: sklearn_evaluation.plot and sklearn_evaluation.table, let’s see an example of how to use them.
Train a model#
First, let’s load some data and split it in training and test set.
data = datasets.make_classification(200, 10, n_informative=5, class_sep=0.65)
X = data[0]
y = data[1]
# shuffle and split training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
Now, we are going to train the data using one of the scikit-learn classifiers.
est = RandomForestClassifier(n_estimators=5)
est.fit(X_train, y_train)
RandomForestClassifier(n_estimators=5)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestClassifier(n_estimators=5)
Input arguments#
Most of the functions require us to pass the class predictions for the test set (y_pred), the scores assigned (y_score) and the ground truth classes (y_true), let’s define such variables.
y_pred = est.predict(X_test)
y_score = est.predict_proba(X_test)
y_true = y_test
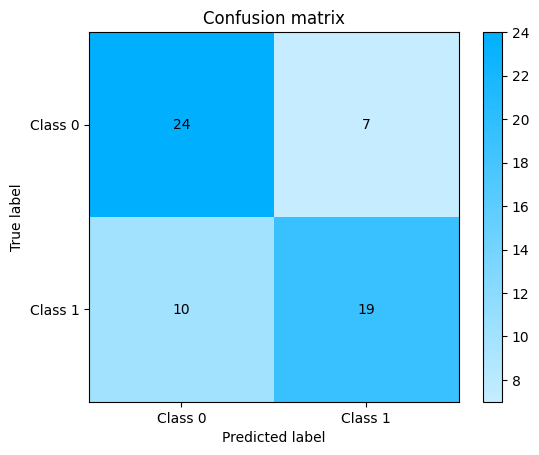
Confusion Matrix#
We can start evaluating our model, the following example shows how to plot a confusion matrix. A confusion matrix visualizes the performances of a classification algorithm. For a two-class classification problem it contains 4 different combinations of predicted and actual values. We can infer four important metrics from this table:
True Positive : Model correctly classified a sample as positive.
False Positive : Model incorrectly classified a sample as positive.
True Negative : Model correctly classified a sample as negative.
False Negative : Model incorrectly classified a sample as negative.
plot.ConfusionMatrix.from_raw_data(y_true, y_pred)
<sklearn_evaluation.plot.classification.ConfusionMatrix at 0x7fb3e80c7dc0>
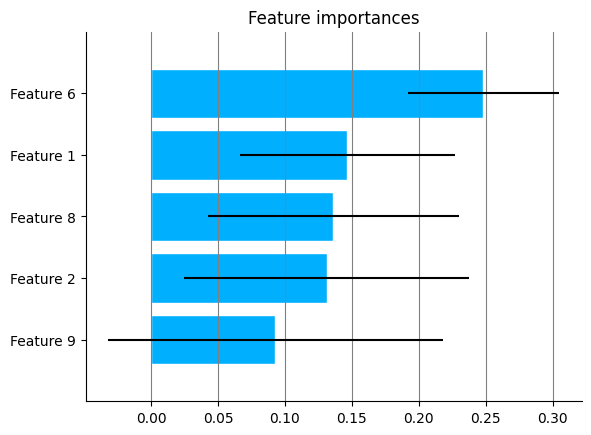
Feature Importances#
Some classifiers (such as sklearn.ensemble.RandomForestClassifier) have feature importances, we can plot them by passing the estimator object to the feature_importances function.
plot.feature_importances(est, top_n=5)
<Axes: title={'center': 'Feature importances'}>
A feature importances function is also available in the table module.
print(table.feature_importances(est))
+----------------+--------------+-----------+
| feature_name | importance | std_ |
+================+==============+===========+
| Feature 6 | 0.248266 | 0.124919 |
+----------------+--------------+-----------+
| Feature 1 | 0.146689 | 0.1065 |
+----------------+--------------+-----------+
| Feature 8 | 0.136269 | 0.0941074 |
+----------------+--------------+-----------+
| Feature 2 | 0.131137 | 0.0804054 |
+----------------+--------------+-----------+
| Feature 9 | 0.092857 | 0.0564867 |
+----------------+--------------+-----------+
| Feature 3 | 0.07278 | 0.0541813 |
+----------------+--------------+-----------+
| Feature 4 | 0.0529661 | 0.0407834 |
+----------------+--------------+-----------+
| Feature 10 | 0.0425884 | 0.0378898 |
+----------------+--------------+-----------+
| Feature 5 | 0.0400068 | 0.0364114 |
+----------------+--------------+-----------+
| Feature 7 | 0.0364408 | 0.0201908 |
+----------------+--------------+-----------+
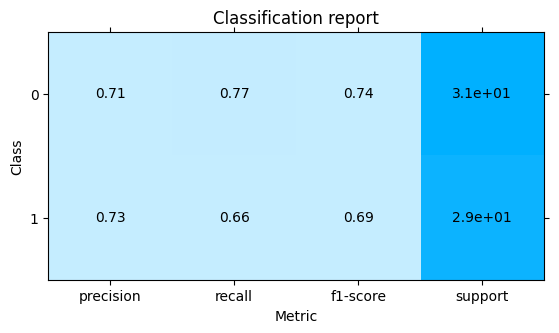
Classification Report#
Precision describes how relevant the retrieved instances of positive class are. Recall is the measure of the model correctly identifying the actual positives. The F1 score can be interpreted as a harmonic mean of the precision and recall.
plot.ClassificationReport.from_raw_data(y_true, y_pred)
<sklearn_evaluation.plot.classification_report.ClassificationReport at 0x7fb3e77e9c60>
Now, let’s see how to generate two of the most common plots for evaluating classifiers: Precision-Recall and ROC.
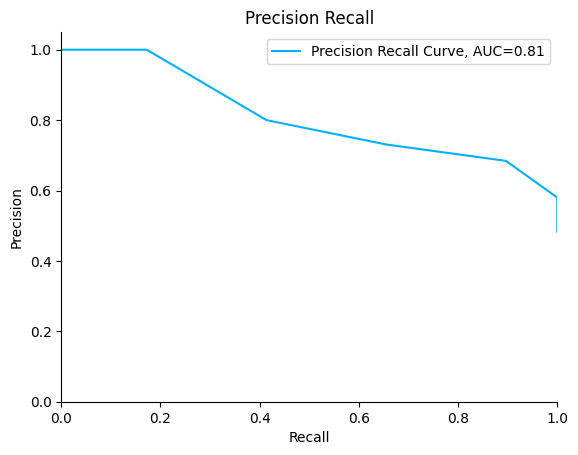
Precision Recall#
Precision-Recall curves summarize the trade-off between the true positive rate and the positive predictive value for a classifier using different probability thresholds. It is often used when the dataset is imbalanced.
plot.PrecisionRecall.from_raw_data(y_true, y_score)
<sklearn_evaluation.plot.precision_recall.PrecisionRecall at 0x7fb3e73f7610>
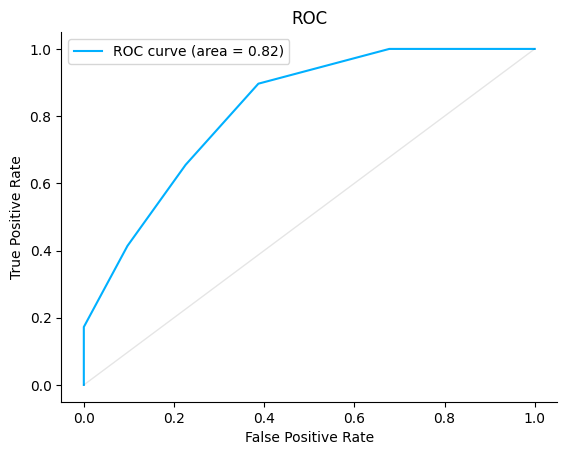
ROC#
An ROC curve (receiver operating characteristic curve) is a graph that shows a classification model’s performance at all classification thresholds. Lowering the classification threshold classifies more items as positive, thus increasing both False Positives and True Positives.
plot.ROC.from_raw_data(y_true, y_score)
<sklearn_evaluation.plot.roc.ROC at 0x7fb3e810fca0>